01
Overview
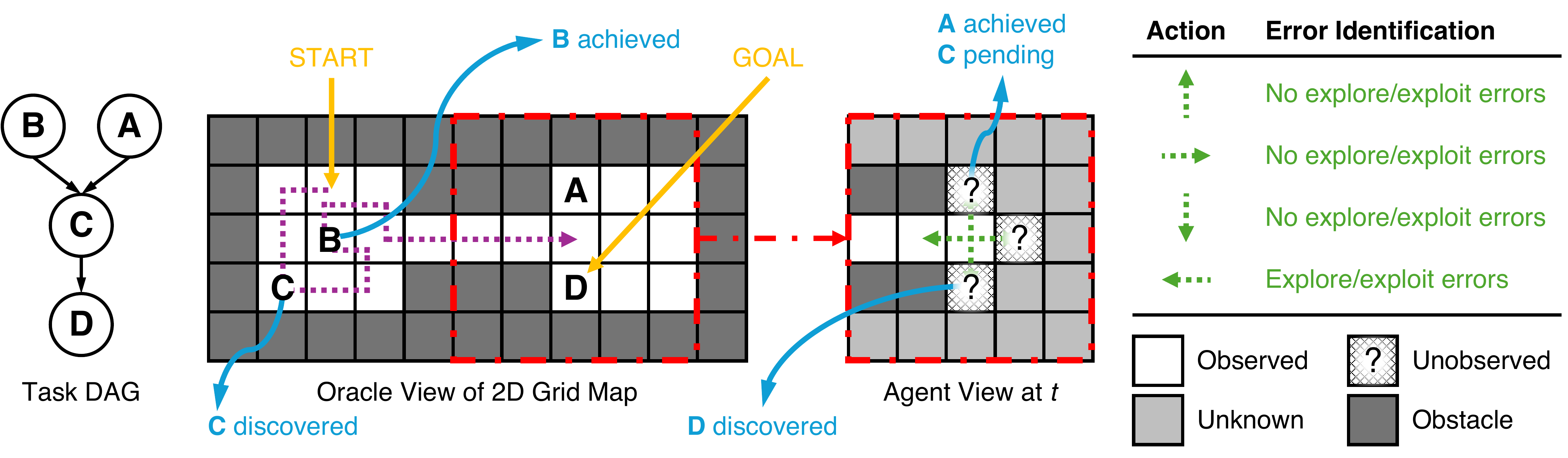
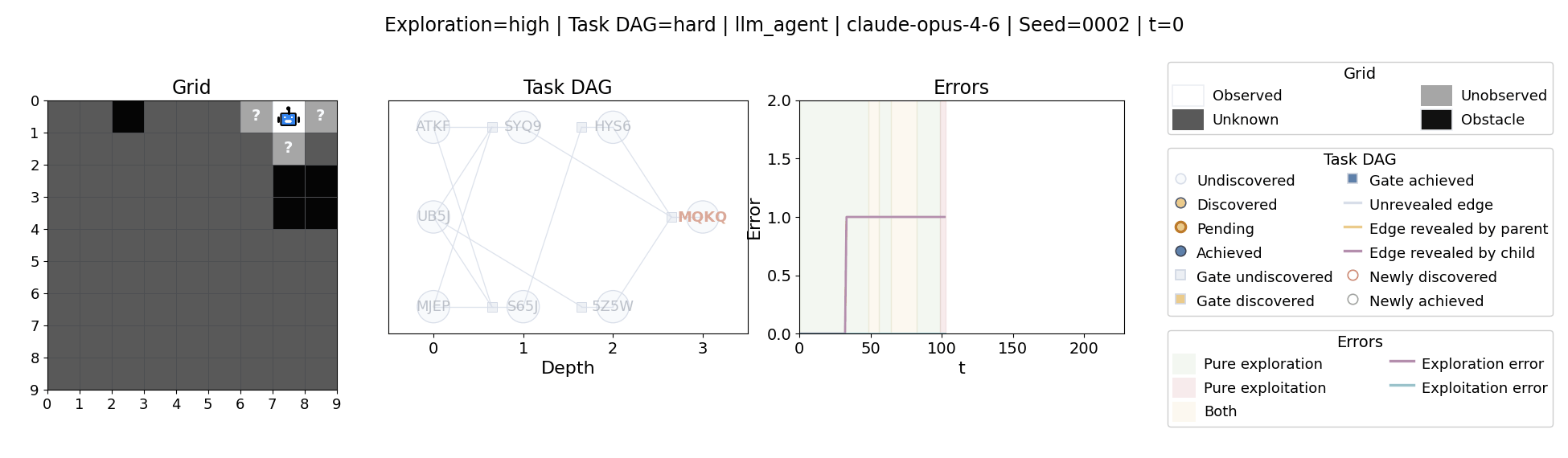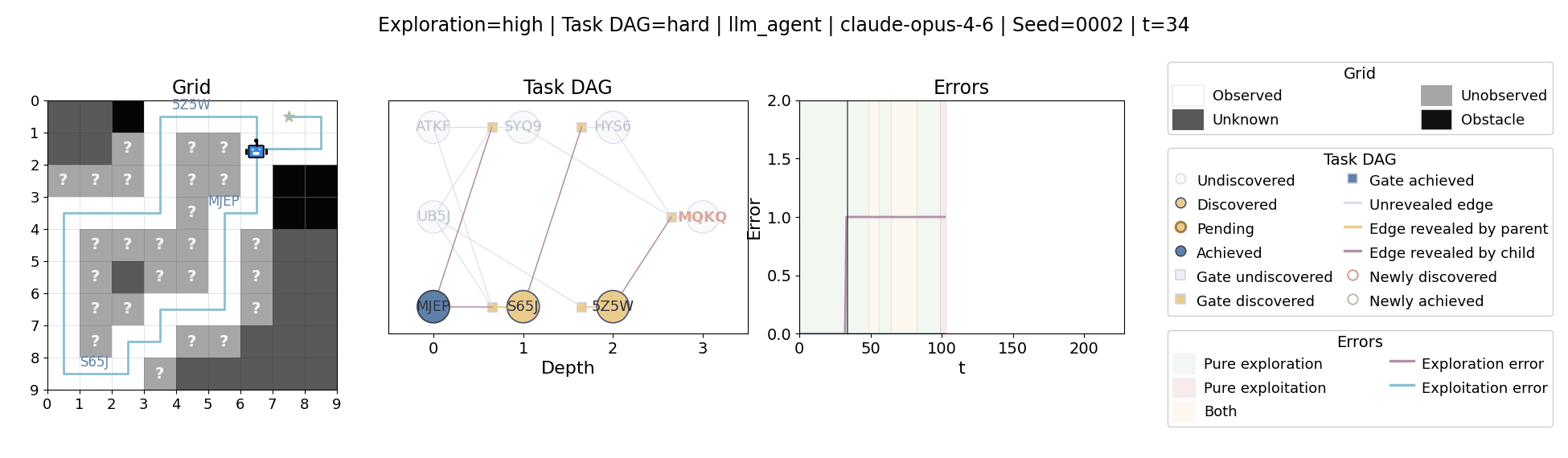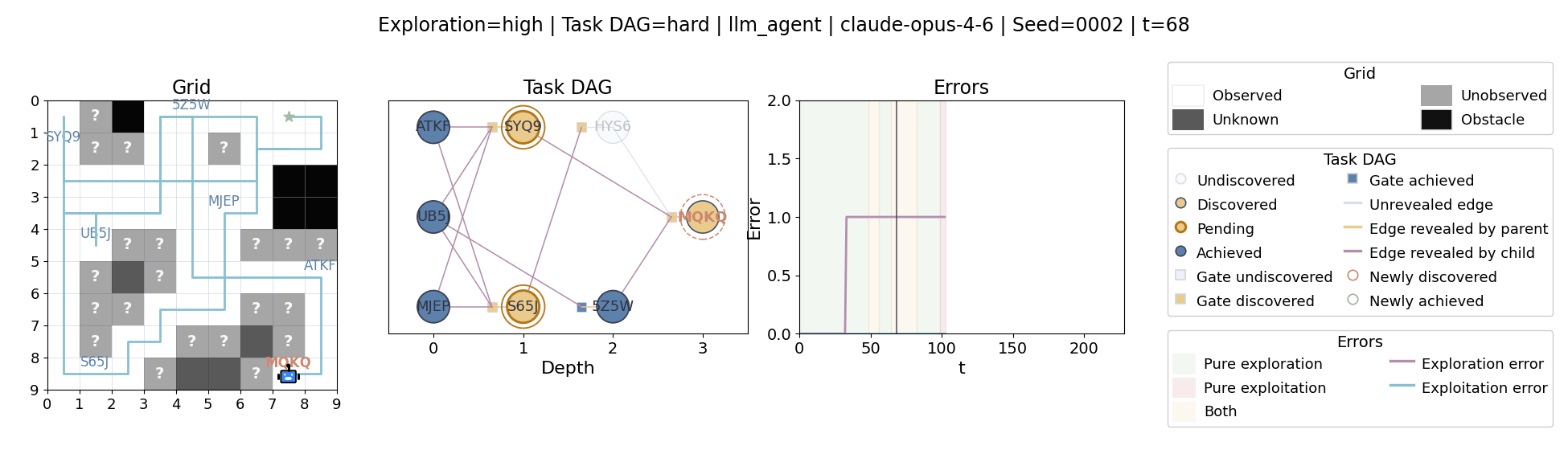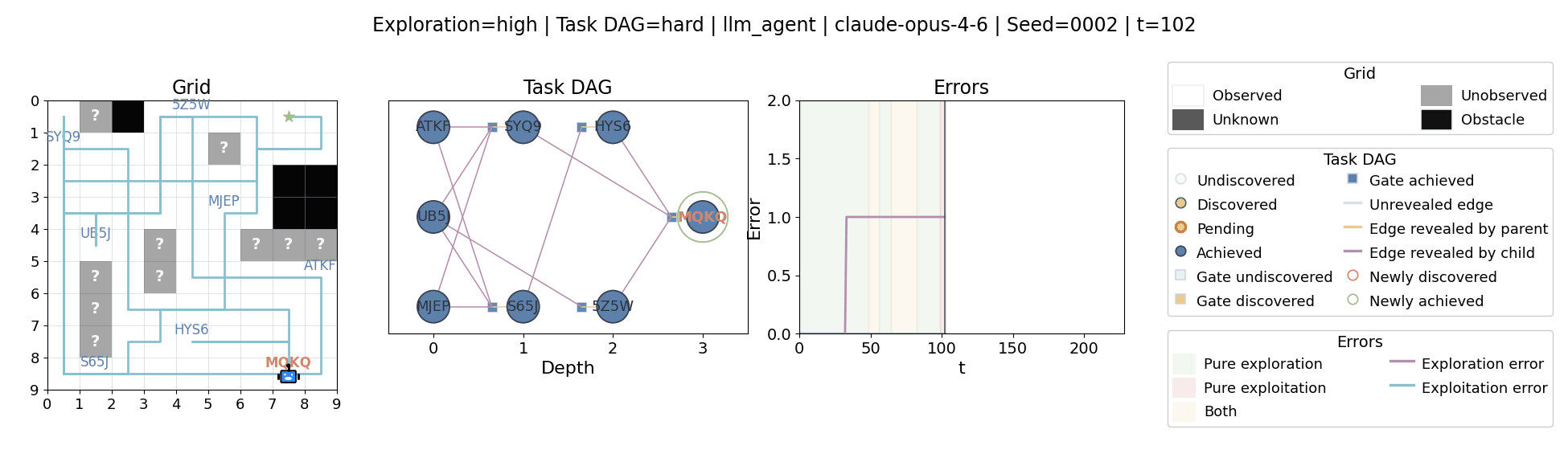
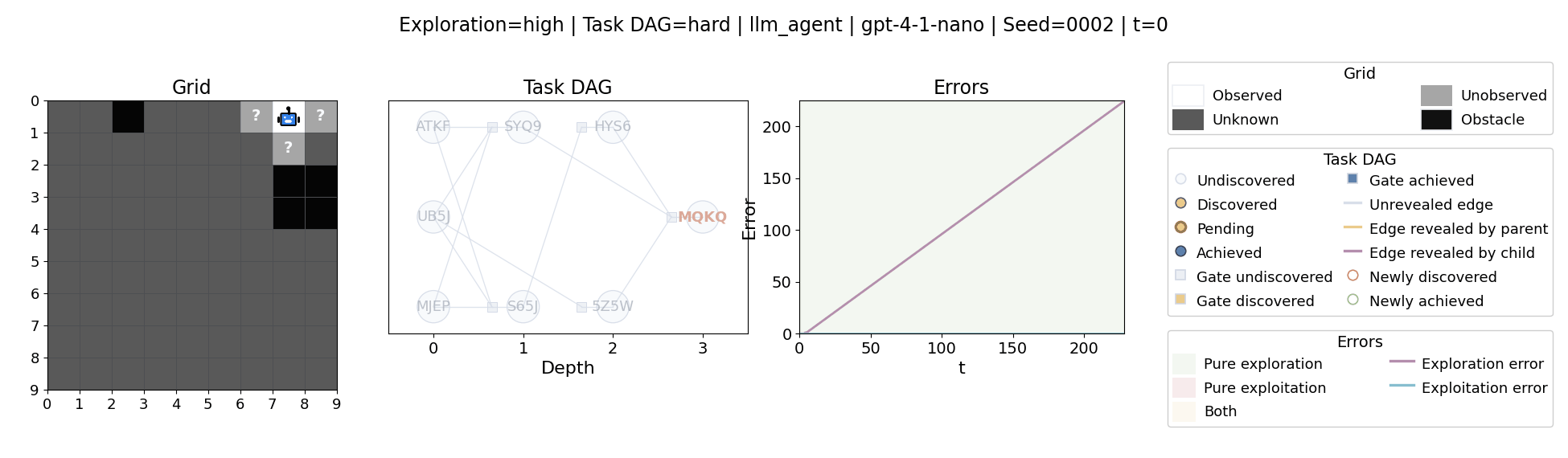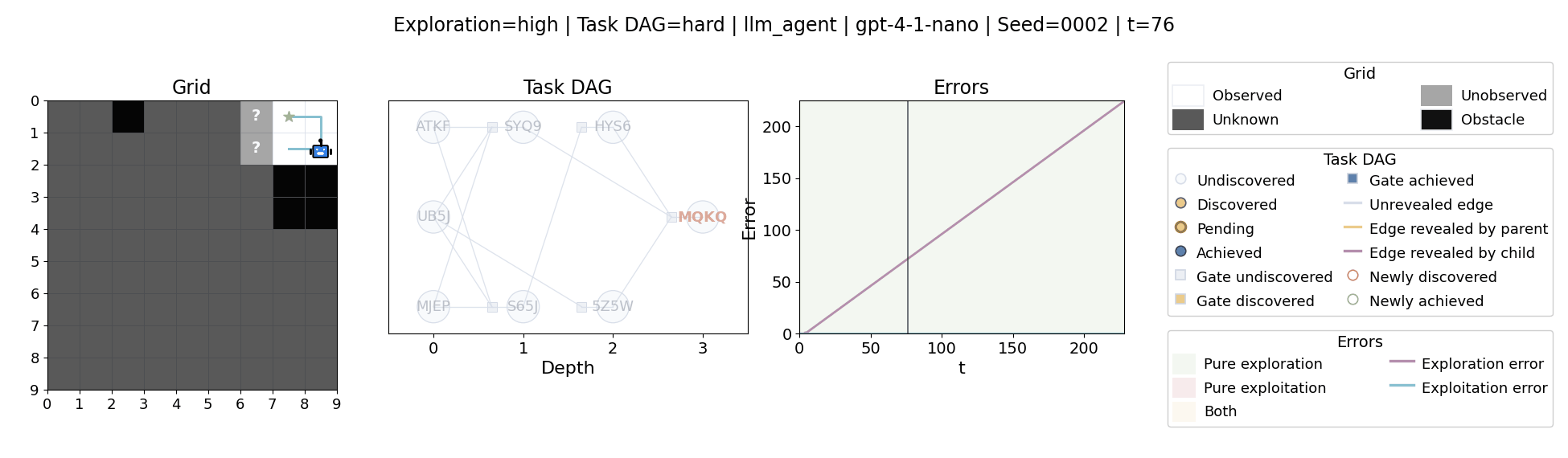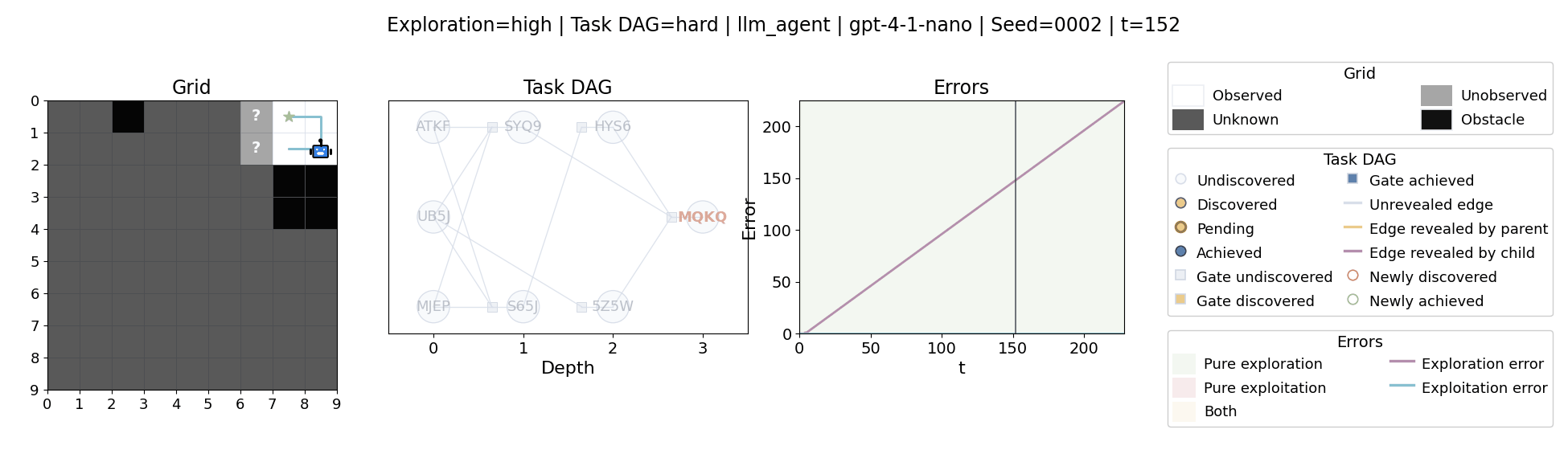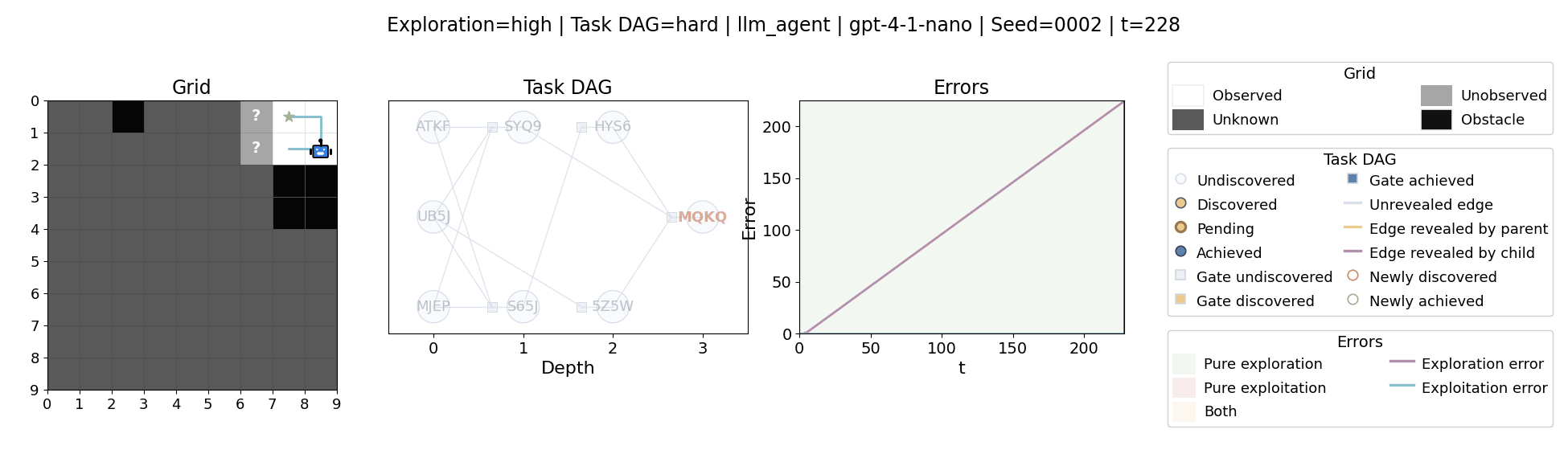
All examples below use exploration=high, task_dag=hard, and seed=2.
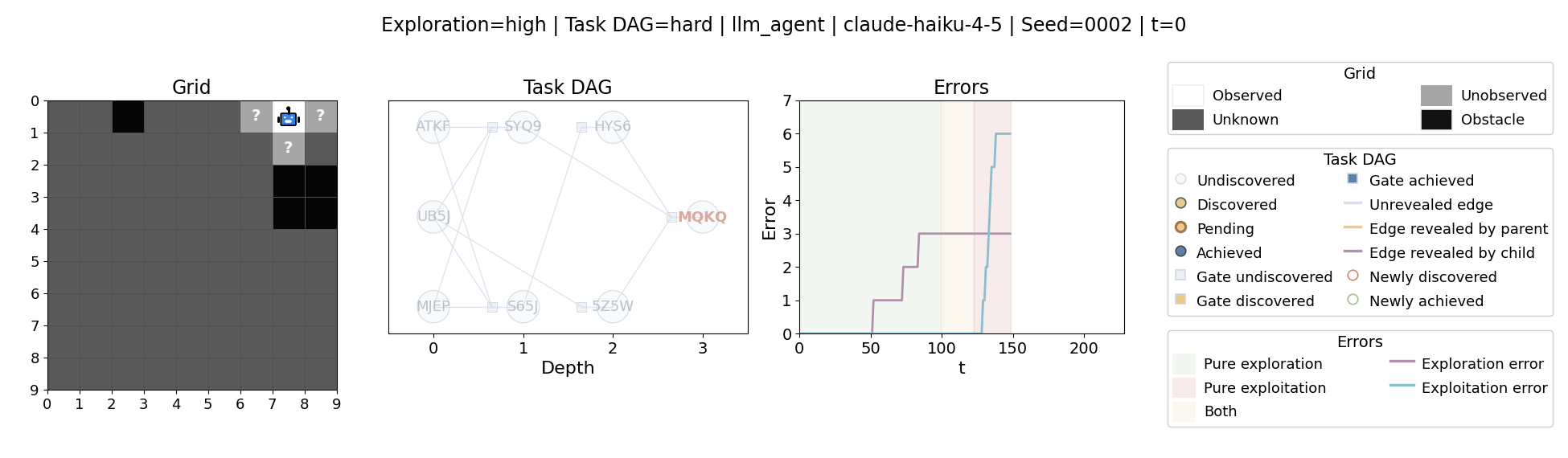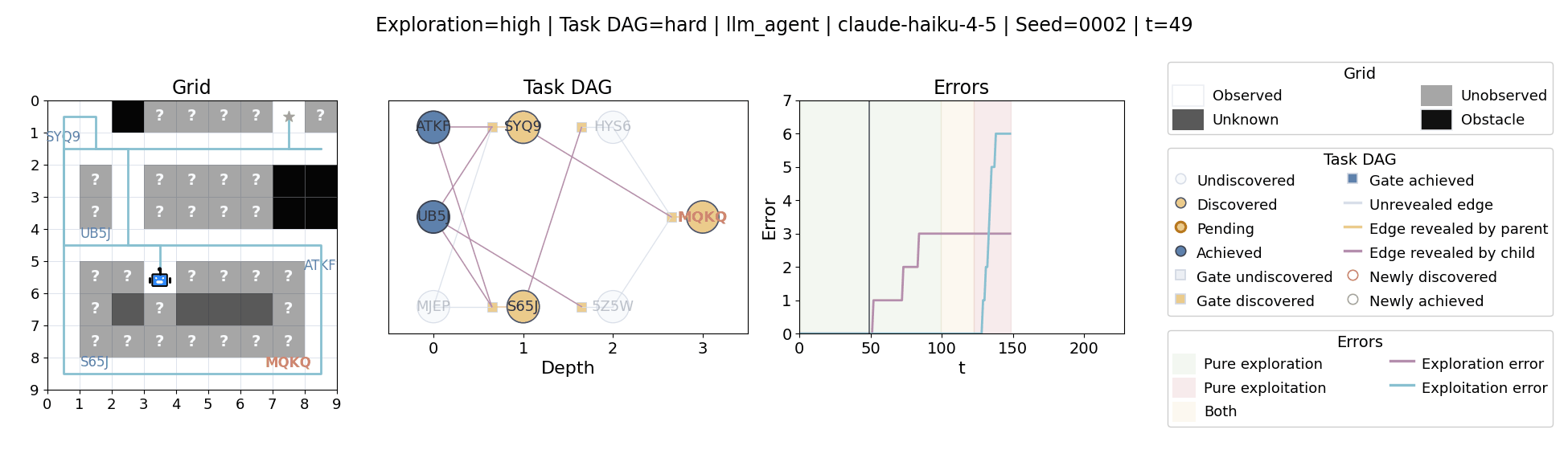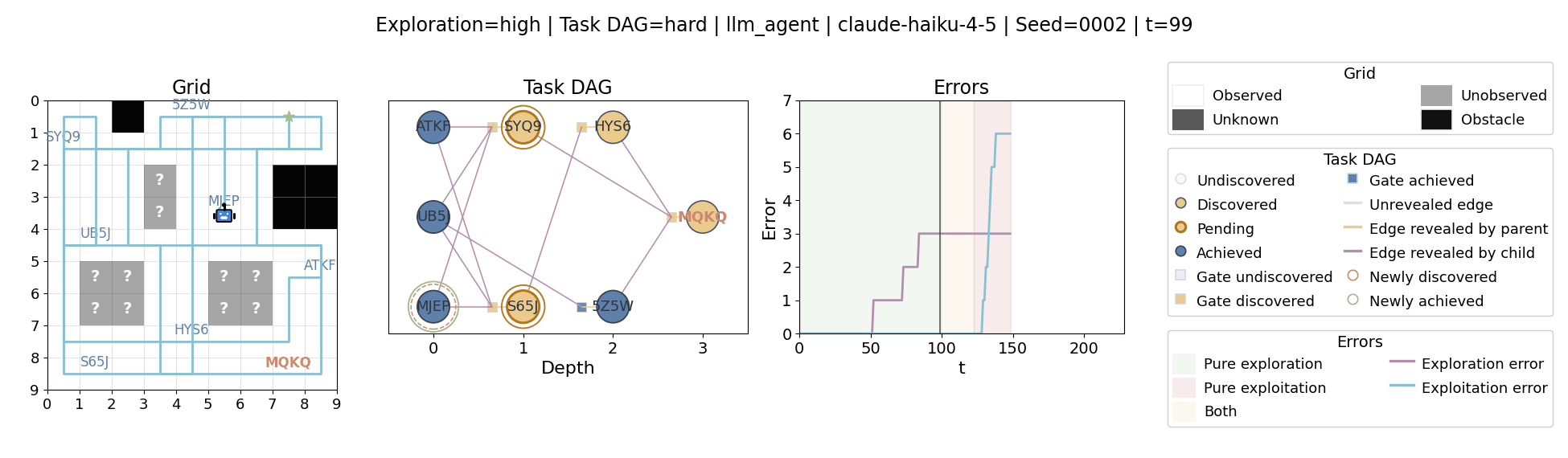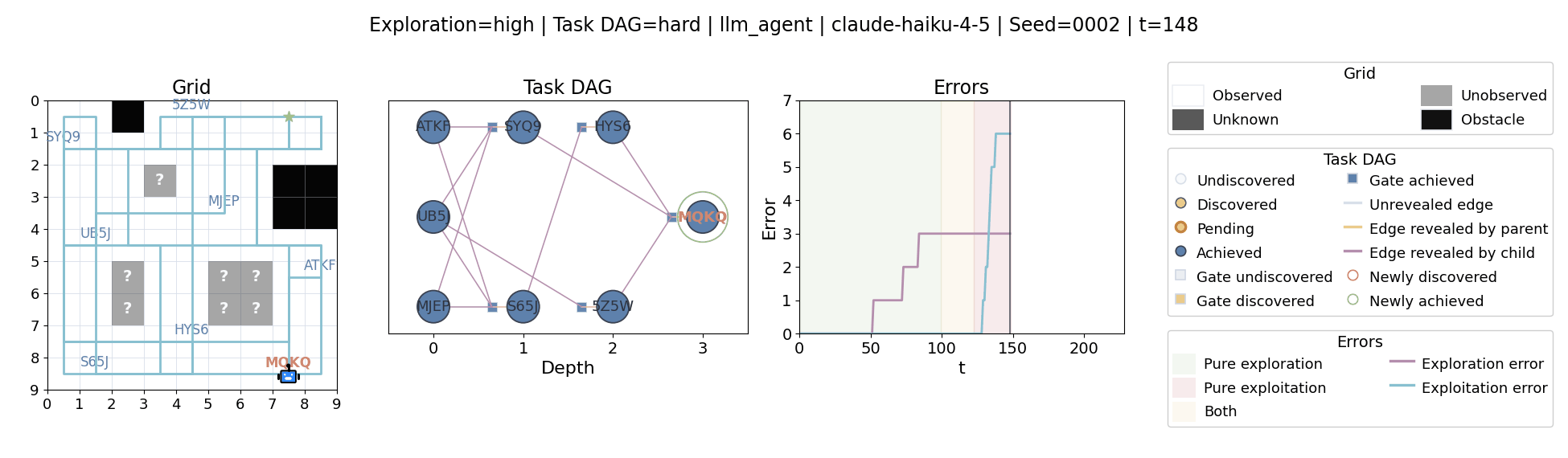
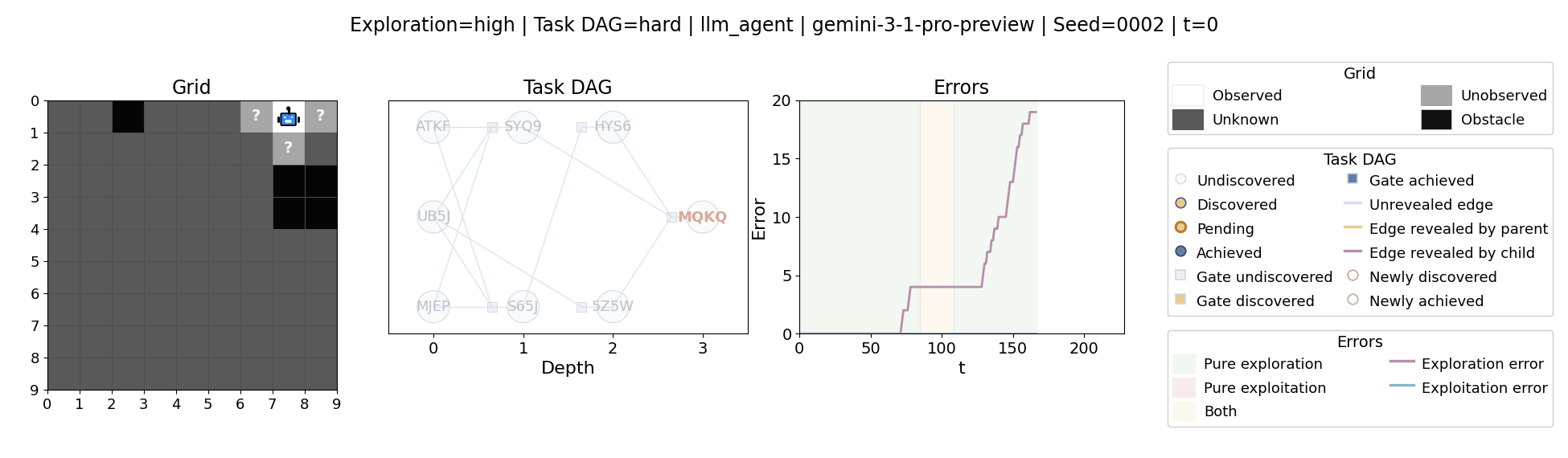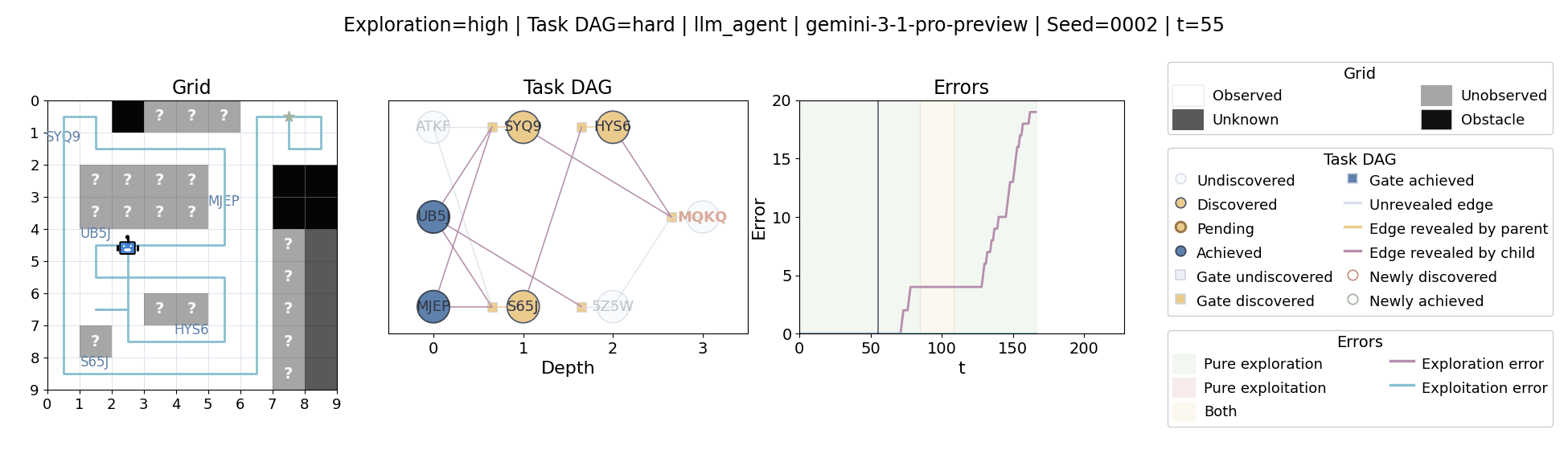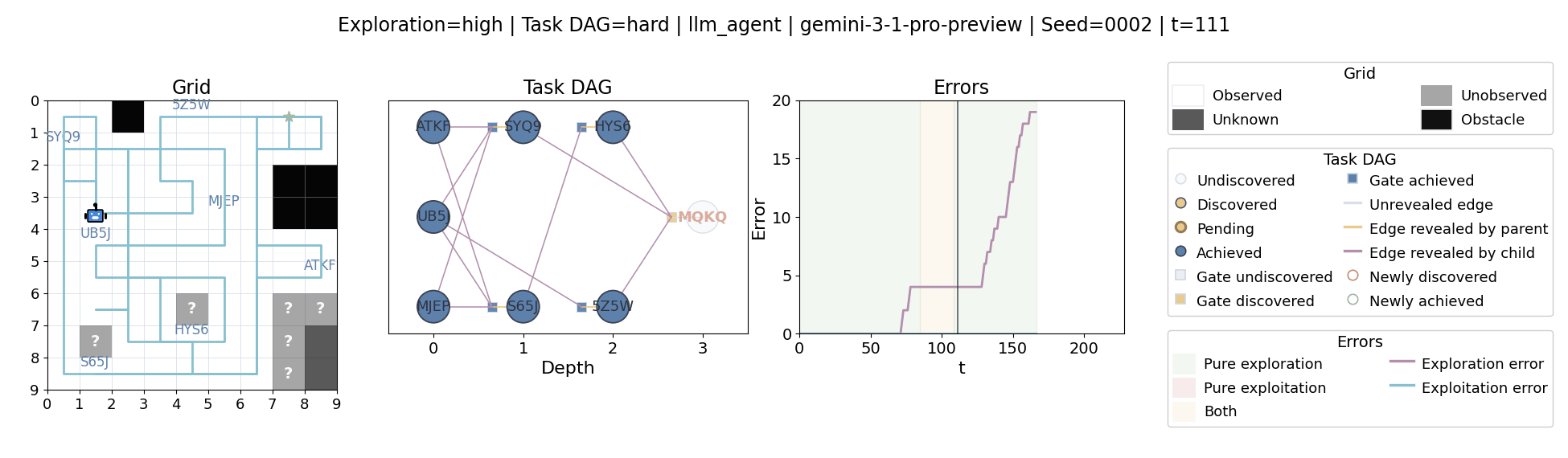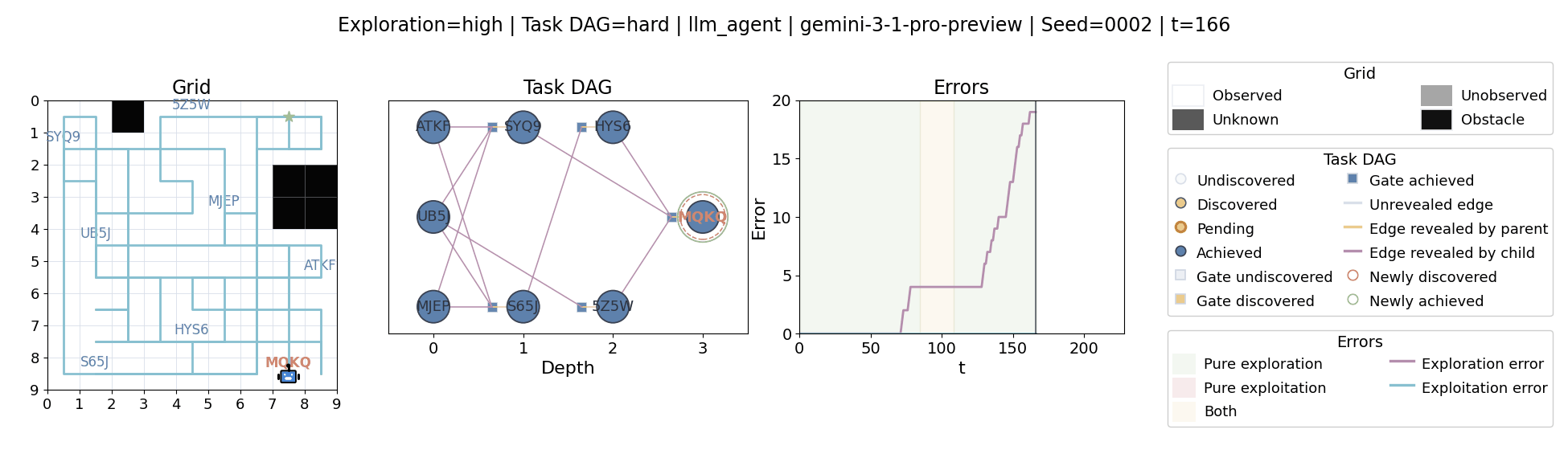
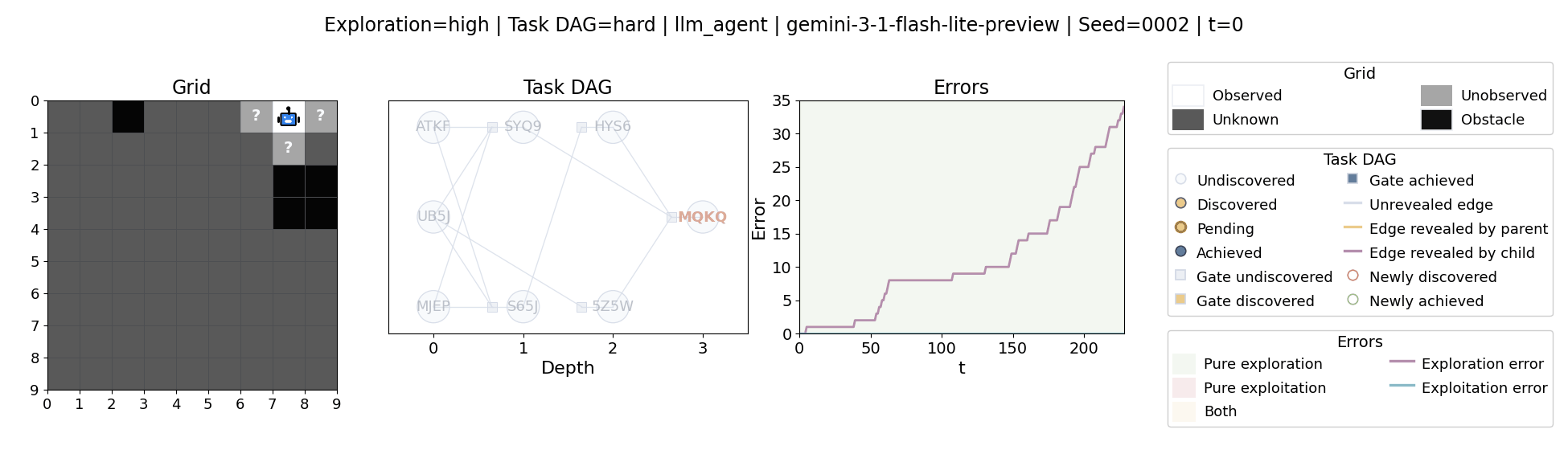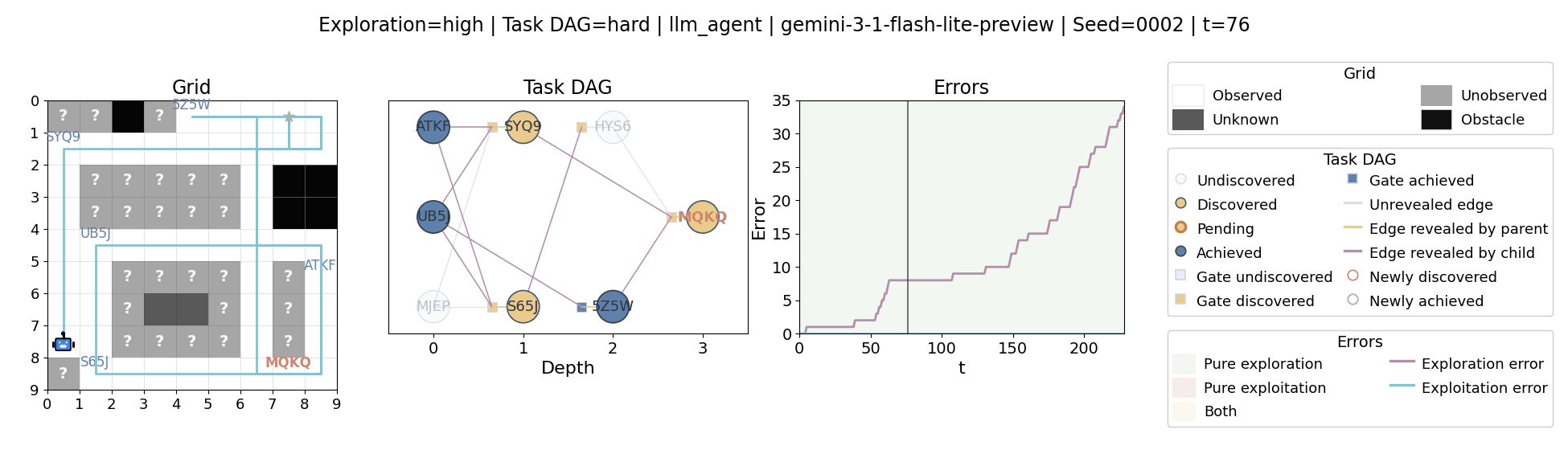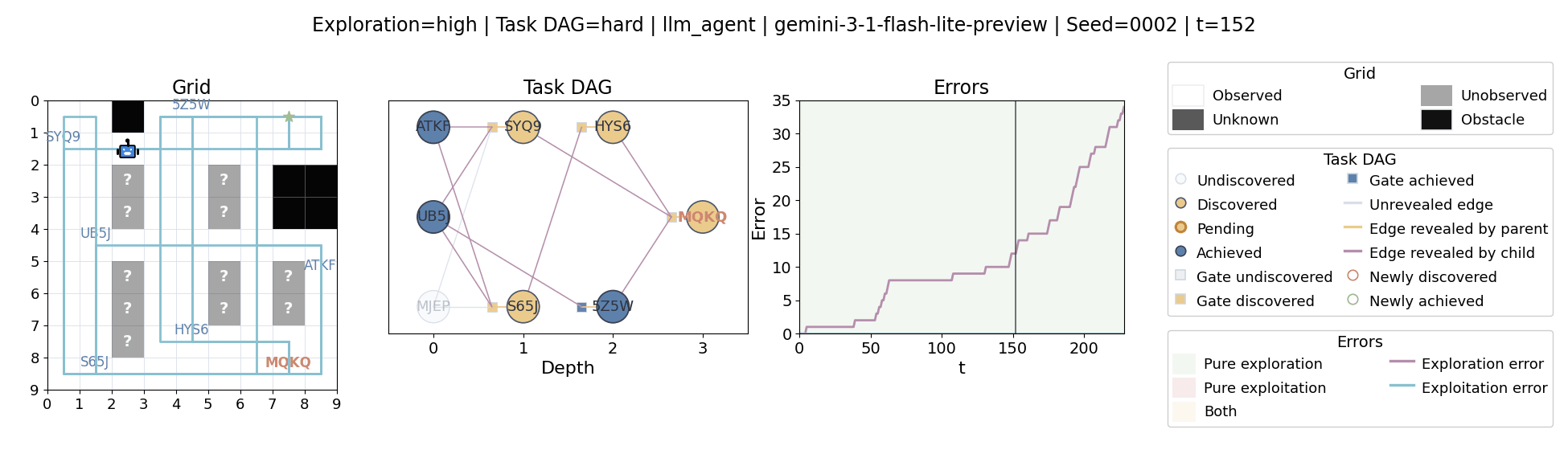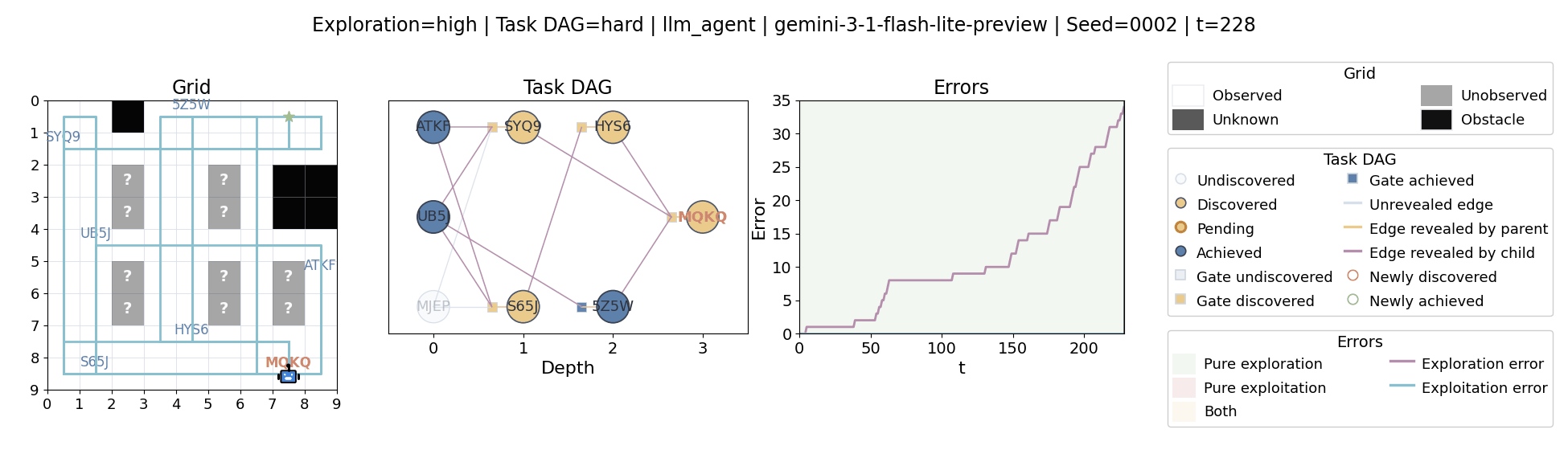
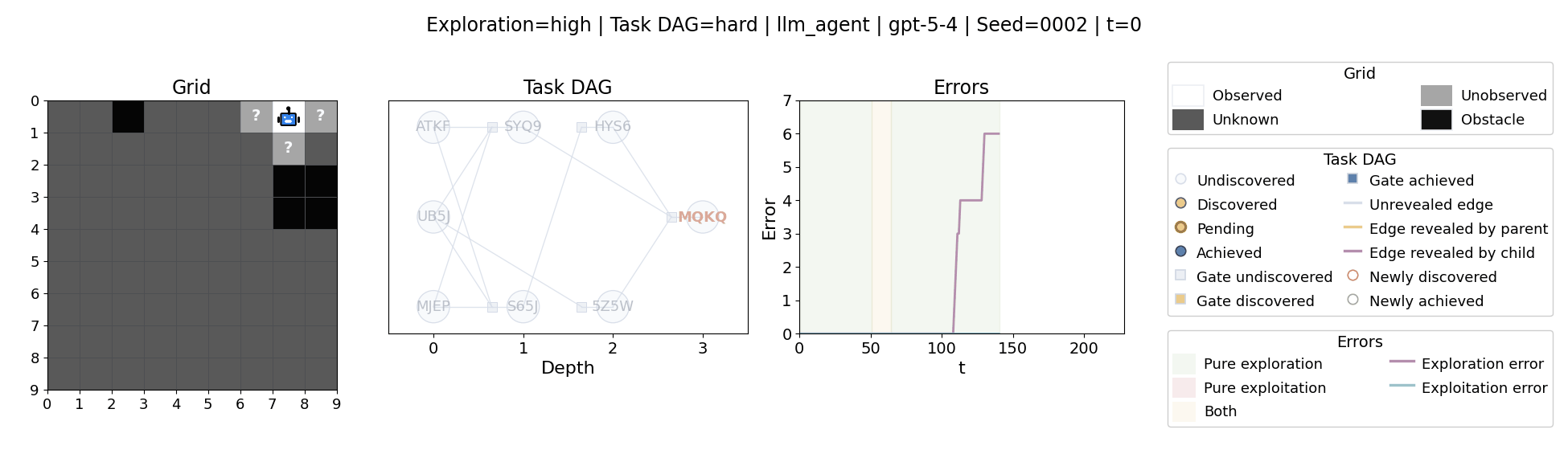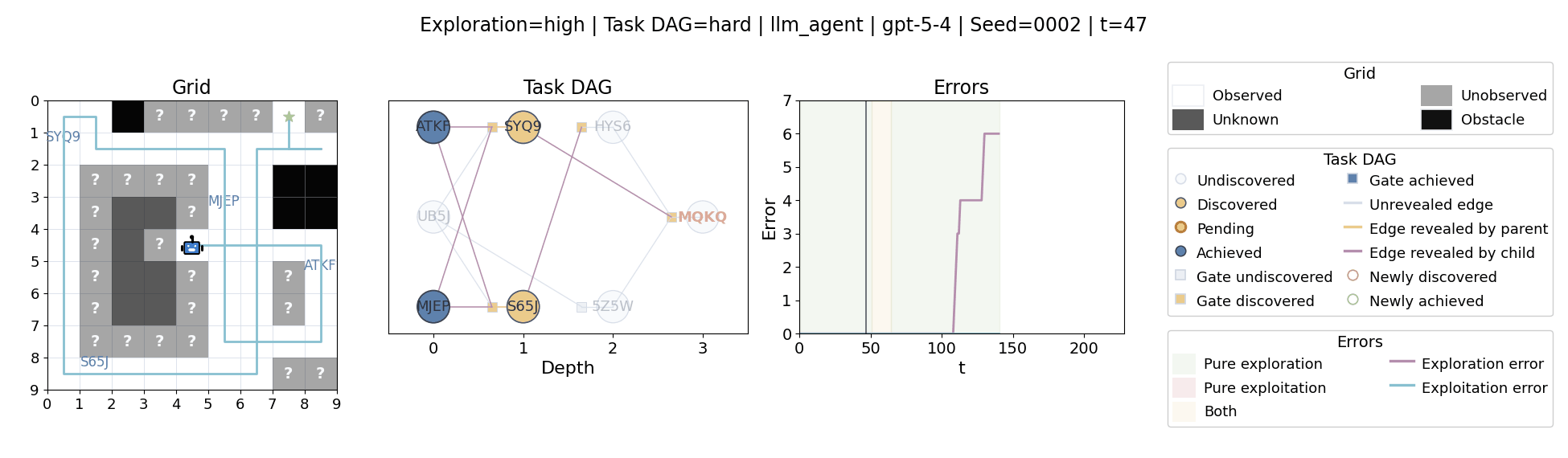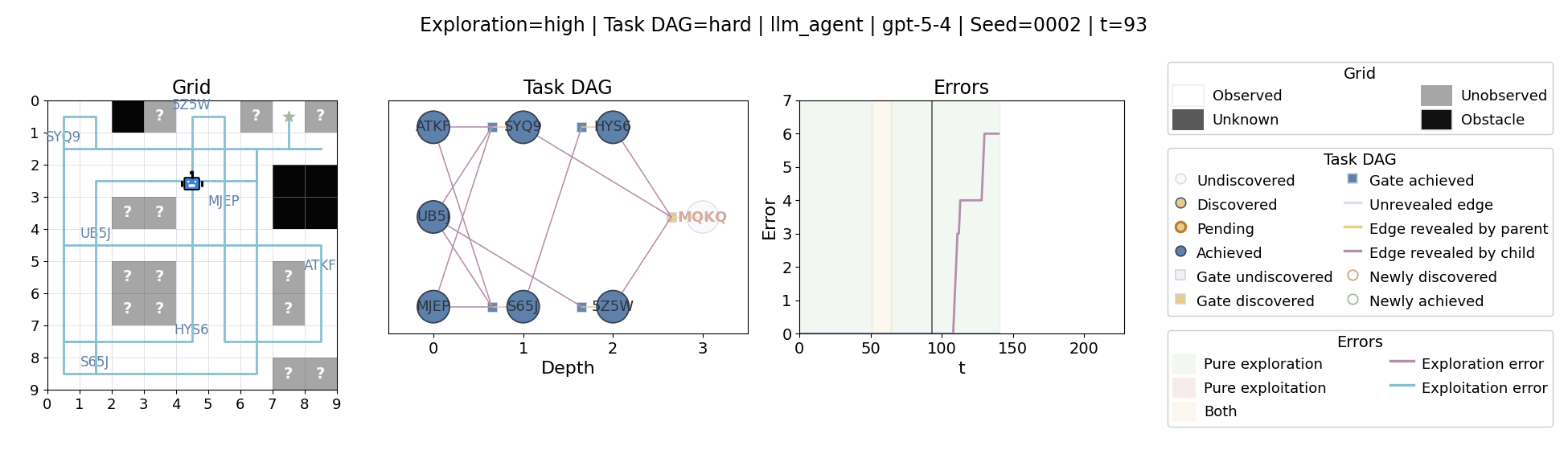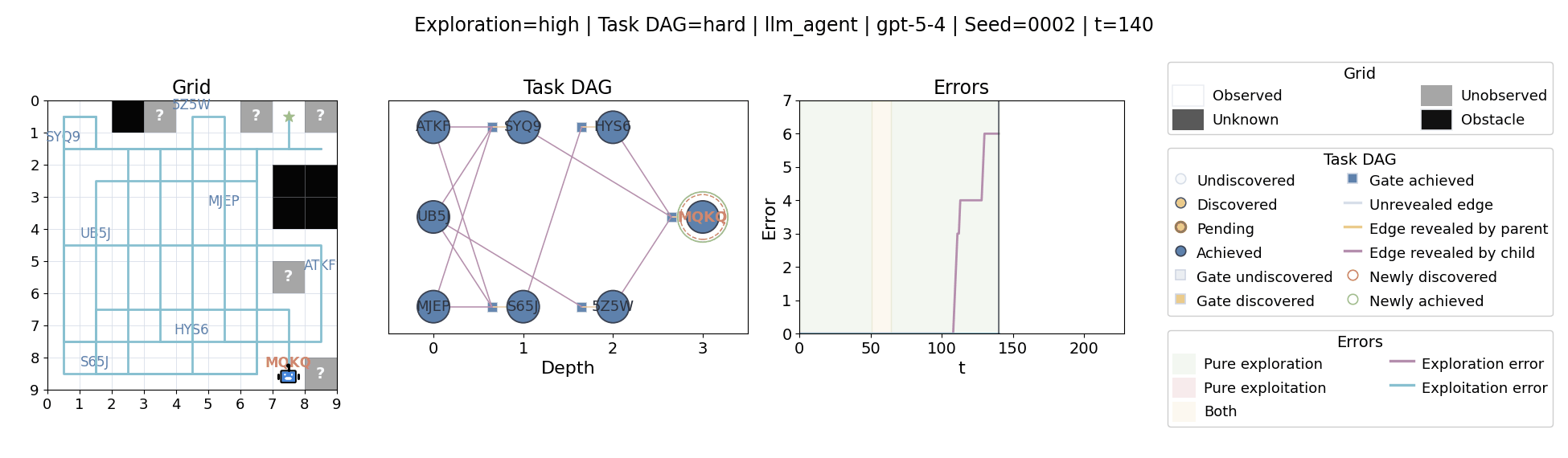
Language model agents are increasingly used in complex open-ended settings, from coding and workflow automation to physical interaction. In these domains, good performance requires both exploring the problem space and exploiting the information gathered so far. Yet most evaluations still collapse these behaviors into a single success number.
We introduce a controllable environment built from partially observable 2D grid maps and unknown symbolic task DAGs, together with a policy-agnostic metric that separates exploration and exploitation errors directly from action trajectories. This allows us to ask not only whether an agent succeeds, but also whether failure came from poor discovery, poor use of discovered information, or both.
Across frontier models, we find that low exploration error is a strong predictor of success, that agents with similar success rates can still behave very differently, and that prompt design together with lightweight harness engineering can significantly reshape failure modes.
The framework measures exploration and exploitation errors from trajectories alone, without access to hidden policies or a single hand-authored reference strategy.
Each task combines a partially observed grid map with a symbolic task DAG, and the generator adjusts exploitation demands and task DAG difficulties.
Symbolic task nodes isolate whether the agent is reasoning from interaction history rather than relying on pretrained semantic priors.
The environment surfaces distinct failure modes across models, prompts, and harnesses, making it useful for agent analysis rather than only ranking.
The environment is built to distinguish failure to discover useful information from failure to use already discovered information. The environment, the error metric, and the evaluation protocol are all designed around that separation.
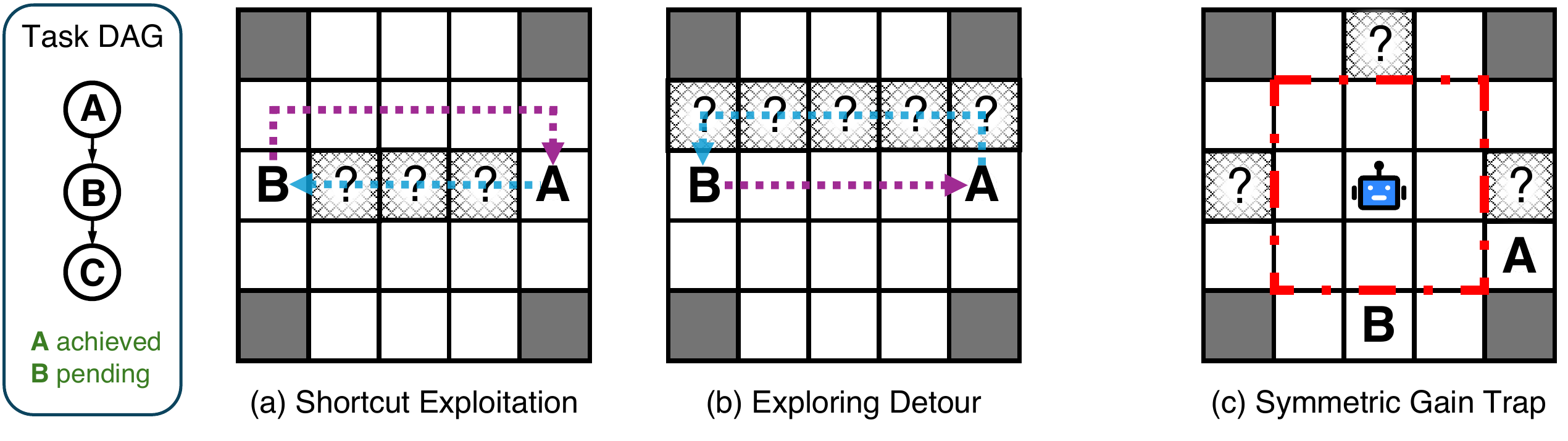
Figure 2. The metric stays strategy-agnostic while still detecting structurally redundant behavior in no-progress segments.
The agent moves through a partially observed 2D grid. Visiting a cell reveals legal moves and any symbolic task node at that location. Discovered nodes reveal local DAG structure but not the locations of related nodes, so progress requires both discovery and later revisitation.
At each timestep the environment constructs a target set of productive destinations: unseen frontier cells, actionable discovered nodes, or both. It combines a gain test with a stale-score over no-progress trajectories so it can allow benign backtracking while penalizing repeated unproductive wandering.
The paper evaluates 13 frontier language models, multiple prompt variants, and explicit harness engineering. The environment reports success, exploration error, and exploitation error, yielding a more informative behavioral profile than success alone.
The main empirical picture is that successful agents first need to discover the right states. Across the evaluated models, exploration error is far more predictive of success than exploitation error, even though both are measurable and both can be improved through intervention.
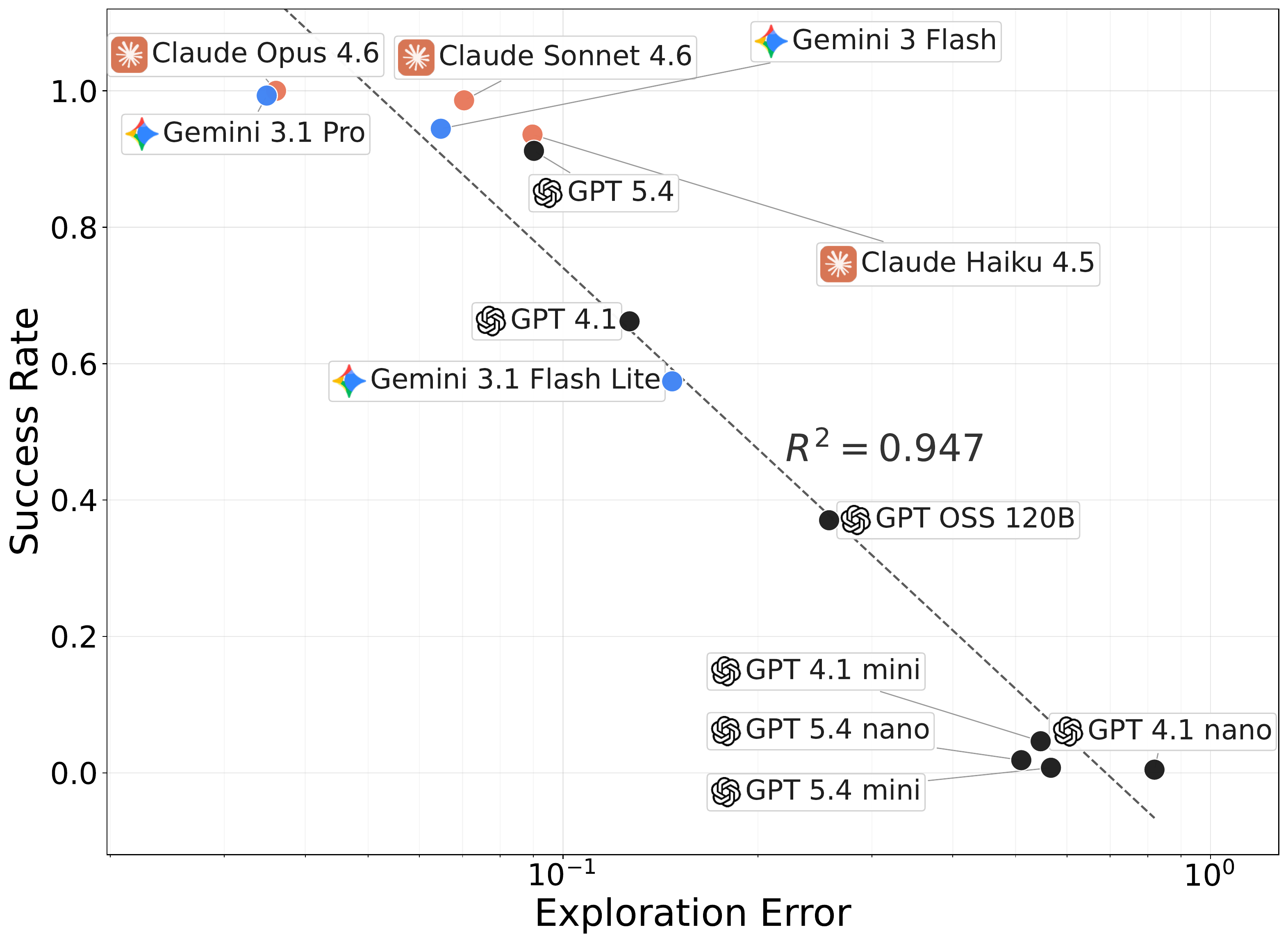
Success rate and exploration error show a strong negative relationship
(R² = 0.947), indicating that poor exploration strongly limits success.
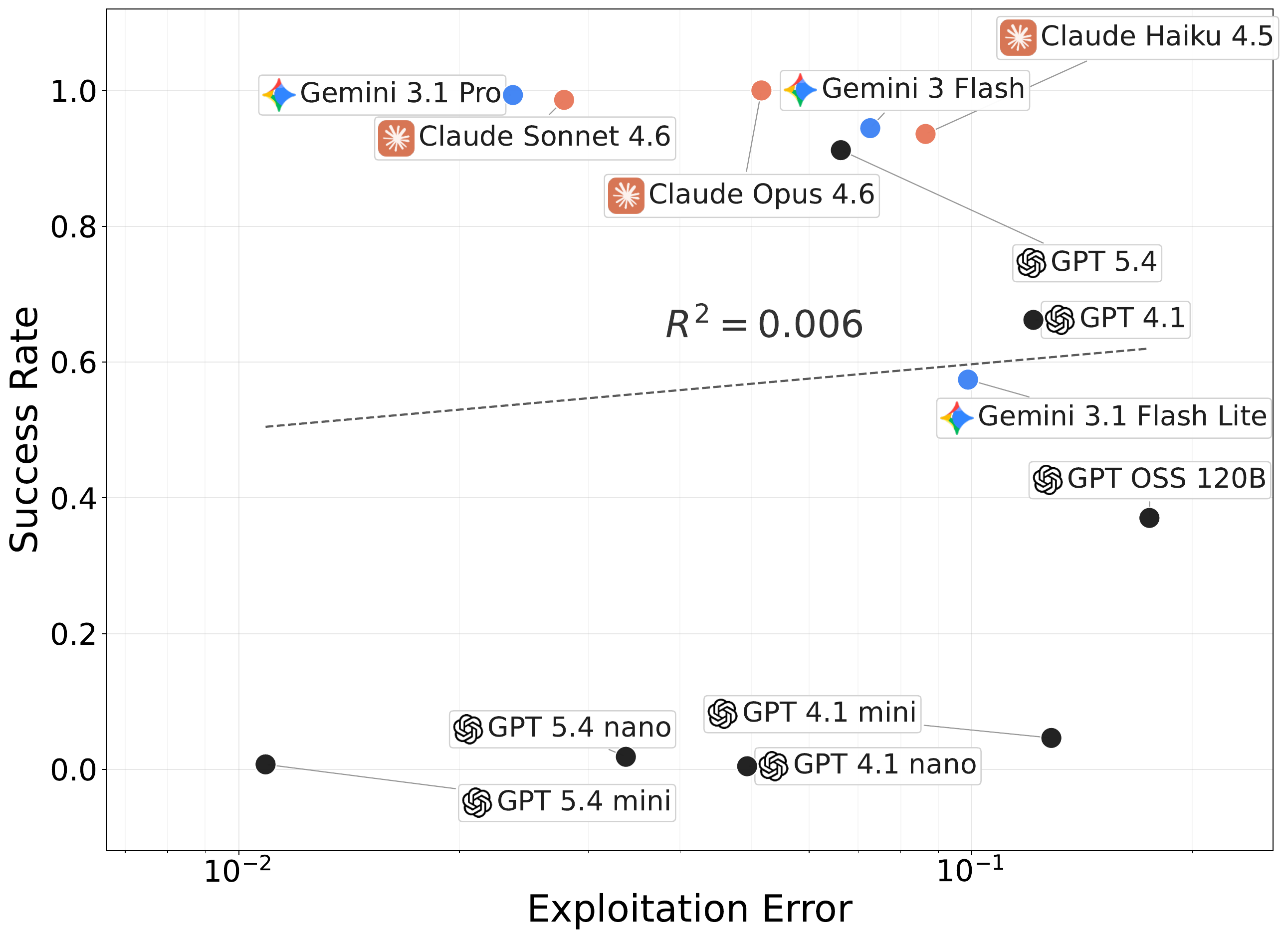
Exploitation error alone is much less predictive of success, because agents that fail to discover key states can still appear locally efficient on what they already know.
The strongest trend in the paper is the link between effective exploration and end-task completion. If an agent does not discover actionable information, it rarely gets the chance to exploit well.
Models with comparable aggregate performance can still differ substantially in when they keep exploring versus when they commit to already discovered goals.
Exploration-focused prompts reduce exploration error, exploitation-focused prompts reduce exploitation error, and structured memory summaries substantially improve success for several models.
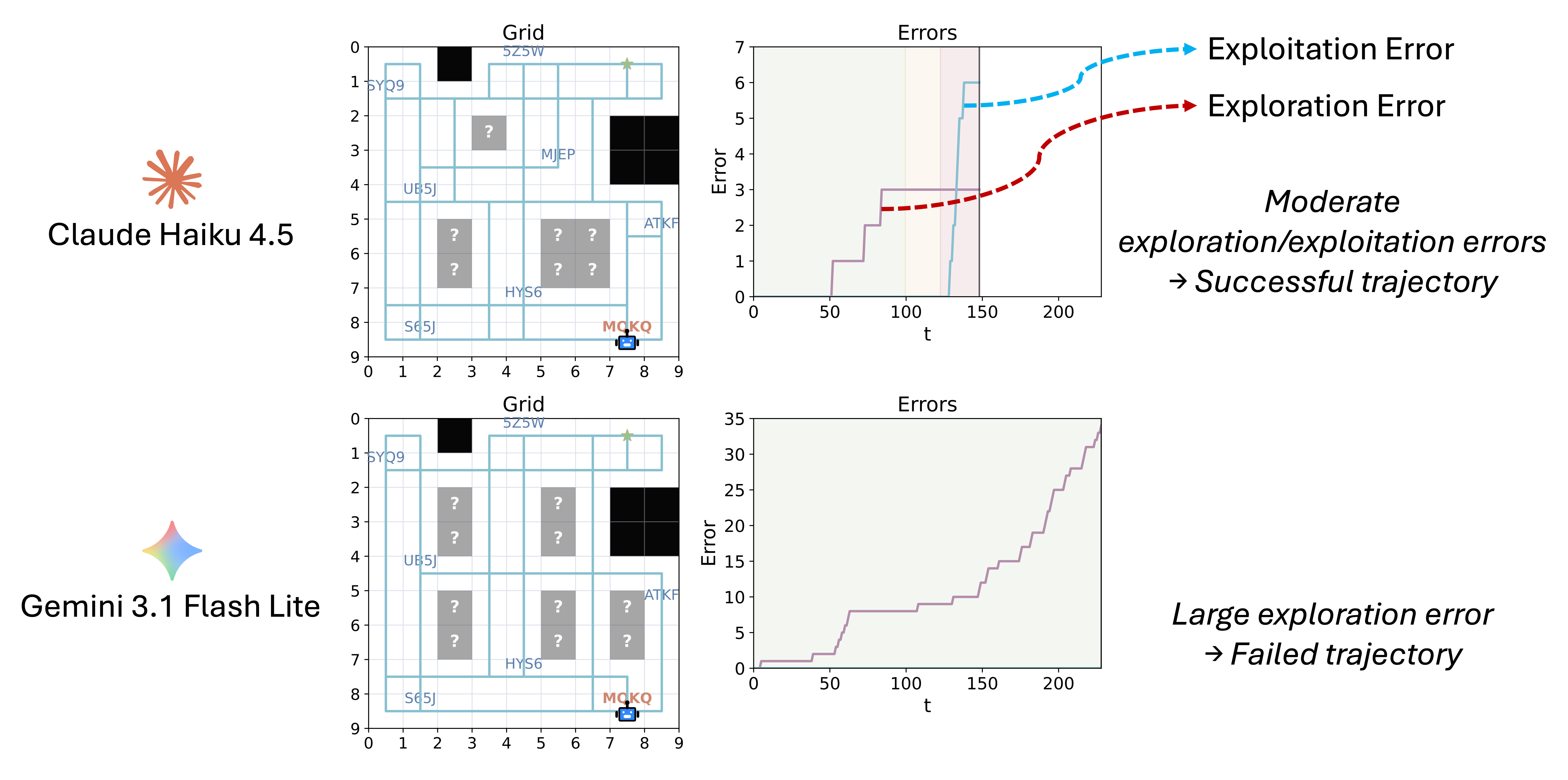
Different models reveal noticeably different exploration and exploitation behaviors even on the same environment episode.
For GPT-4.1, an exploration-focused prompt raises success from 63% to 80% and lowers exploration error from 0.123 to 0.099. Explicit structured memory summaries raise GPT-4.1 from 63.0% to 92.6% success and Gemini 3.1 Flash Lite from 51.9% to 88.9%.
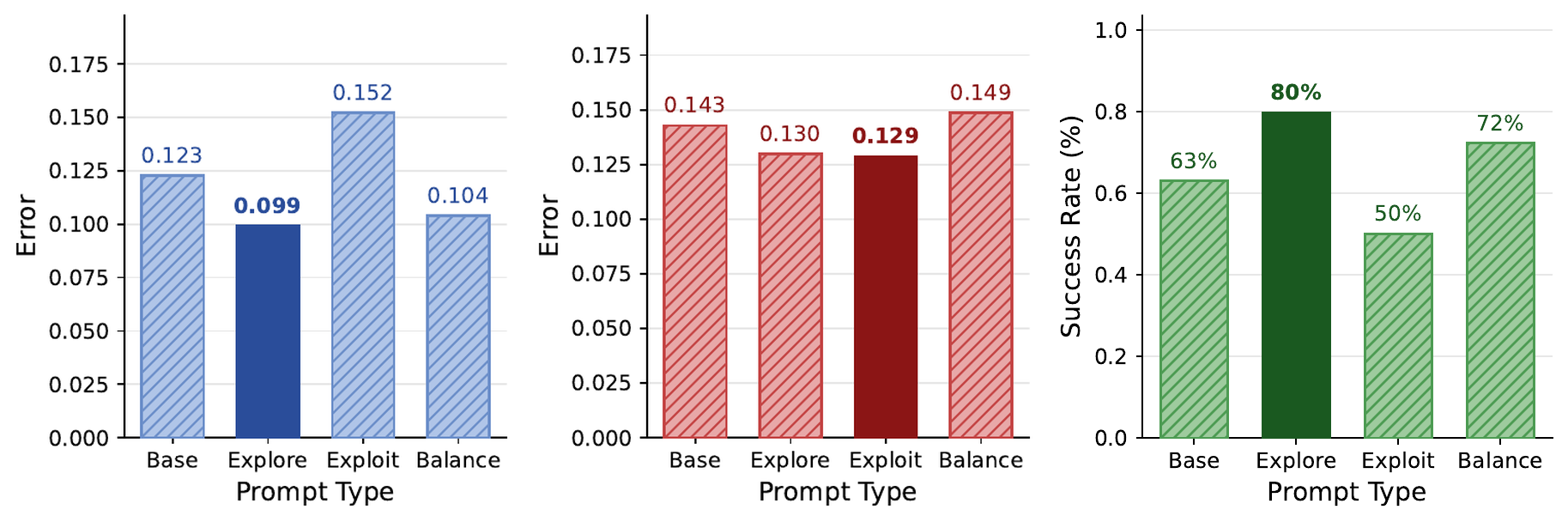
Left to right: GPT-4.1 exploration error, exploitation error, and success rate across prompt types.
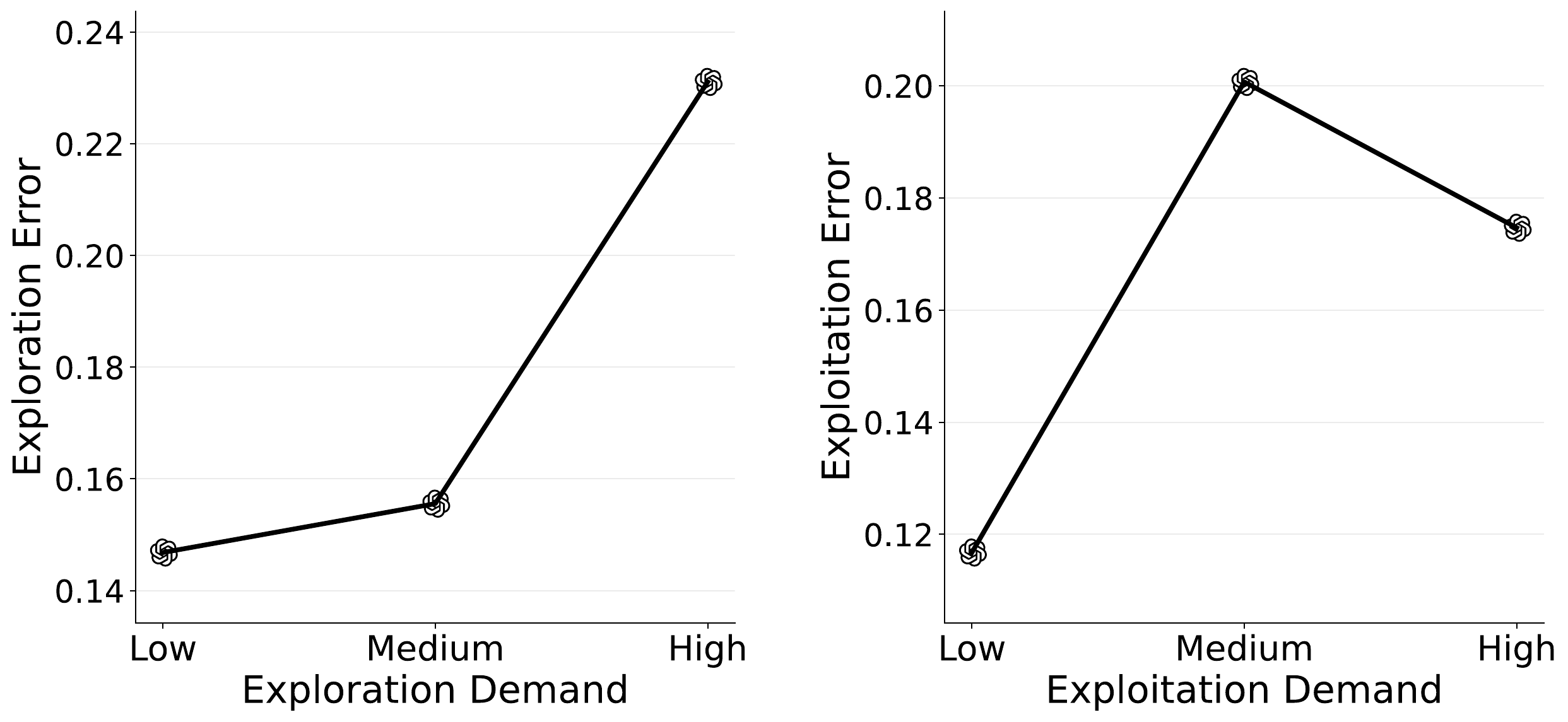
Increasing exploration demand clearly increases exploration error.
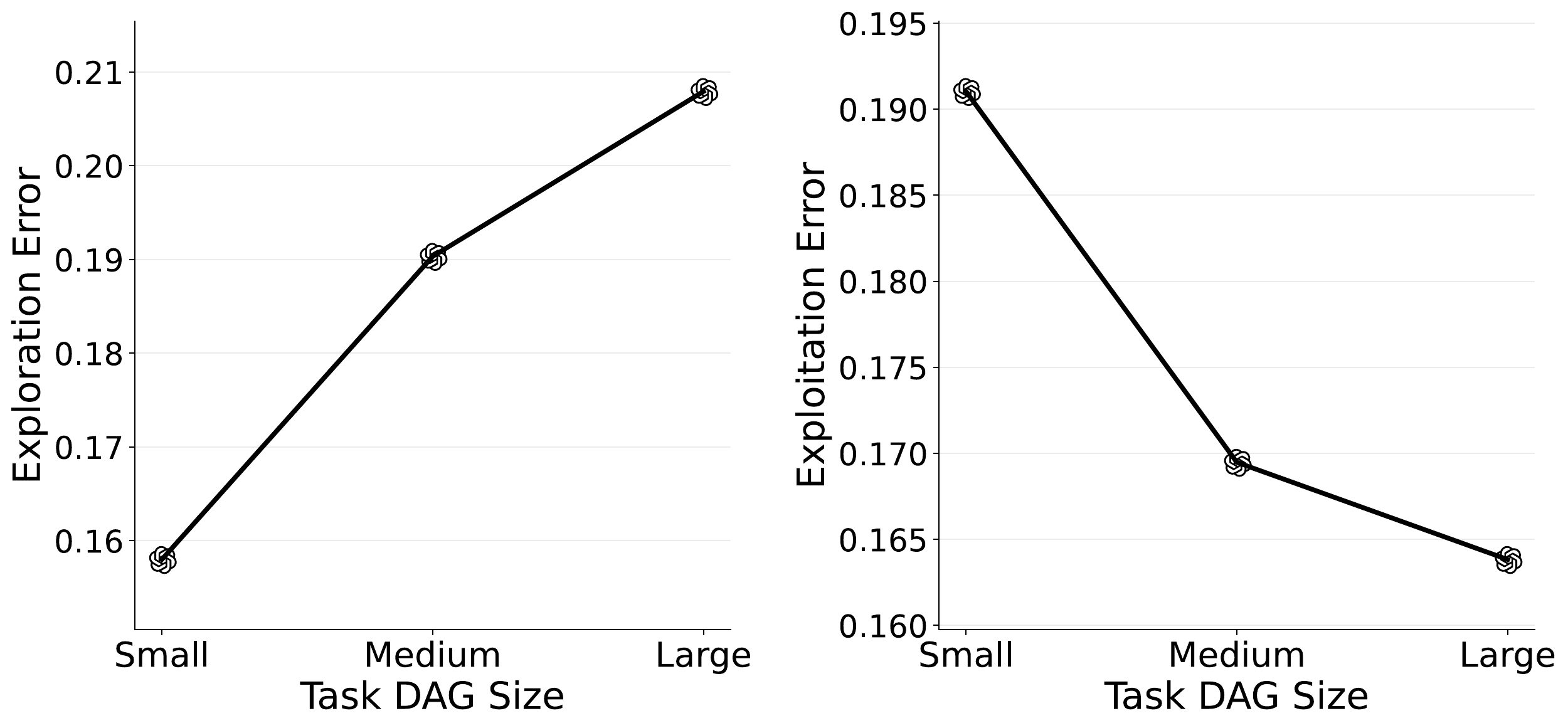
Increasing symbolic task complexity shifts the balance between exploration and exploitation burden.
The repository includes environment generation, simulation, analysis scripts, visualization utilities, and tests for reproducing the environment. More details can be found in the GitHub repository.
pip install -e .
bash scripts/setup_llm_keys.sh
source ~/.symbolic_environment_llm_keys
symbolic-environment simulate \
--exploration-level high \
--task-dag-difficulty hard \
--seed 0 \
--agent llm_agent \
--llm-provider azure \
--llm-model gpt-4.1 \
--llm-prompt-set reasoning-exploration \
--gif@article{park2026exploration,
title={Exploration and Exploitation Errors Are Measurable for Language Model Agents},
author={Jaden Park and Jungtaek Kim and Jongwon Jeong and Robert D. Nowak and Kangwook Lee and Yong Jae Lee},
journal={arXiv preprint arXiv:2604.13151},
year={2026}
}